uptime
$ uptime 11:50:22 up 112 days, 23:58, 1 user, load average: 0.00, 0.00, 0.00
- 该命令可以大致的看出计算机的整体负载情况,load average 后的数字分别表示计算机在 1min、5min、15min 内的平均负载。
dmesg | tail
$ dmesg | tail [9763086.775830] [UFW BLOCK] IN=eth0 OUT= MAC=52:54:00:32:21:01:fe:ee:ff:ff:ff:ff:08:00 SRC=192.166.219.136 DST=10.154.173.244 LEN=52 TOS=0x00 PREC=0x00 TTL=47 ID=52781 PROTO=TCP SPT=60592 DPT=80 WINDOW=501 RES=0x00 ACK FIN URGP=0 [9763099.437109] [UFW BLOCK] IN=eth0 OUT= MAC=52:54:00:32:21:01:fe:ee:ff:ff:ff:ff:08:00 SRC=192.166.219.136 DST=10.154.173.244 LEN=52 TOS=0x00 PREC=0x00 TTL=47 ID=52782 PROTO=TCP SPT=33392 DPT=80 WINDOW=496 RES=0x00 ACK FIN URGP=0 [9763113.794092] [UFW BLOCK] IN=eth0 OUT= MAC=52:54:00:32:21:01:fe:ee:ff:ff:ff:ff:08:00 SRC=109.248.9.251 DST=10.154.173.244 LEN=40 TOS=0x00 PREC=0x00 TTL=238 ID=15434 PROTO=TCP SPT=43204 DPT=2122 WINDOW=1024 RES=0x00 SYN URGP=0 [9763115.232853] [UFW BLOCK] IN=eth0 OUT= MAC=52:54:00:32:21:01:fe:ee:ff:ff:ff:ff:08:00 SRC=122.192.13.180 DST=10.154.173.244 LEN=81 TOS=0x08 PREC=0x60 TTL=51 ID=17973 PROTO=UDP SPT=49713 DPT=443 LEN=61
- 打印内核环形缓存区中的内容,可以用来查看一些错误,通过 dmesg 可以快速判断是否有导致系统性能异常的问题
上面例子的意思是防火墙被锁,原因是用的是云服务商的机子,端口之类的不是防火墙这个来设置,是在安全组里面设置
vmstat
$ vmstat 1 procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0 32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0 32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0 32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0 32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
- 打印进程、内存、交换分区、IO 和 CPU 等的统计信息;
- vmstat 的格式如下:
vmstat [options] [delay [count]]
vmstat 第一次输出表示从开机到 vmstat 运行时的平均值;剩余输出的都是在指定的时间间隔内的平均值,上述例子中 delay 的值设置为 1,除第一次以外,剩余的都是 1 秒统计一次,count 未设置,将会一直循环打印。
$ vmstat 10 3 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 210456 116996 709272 0 0 1 11 1 1 0 0 99 0 0 0 0 0 210116 117000 709288 0 0 0 32 145 231 0 0 99 0 0 0 0 0 210332 117008 709256 0 0 0 20 179 305 0 0 99 0 0
上述的例子中 delay 设置为 10,count 设置为 3,表示每行打印 10 秒内的平均值,只打印 3 次。
需要检查的列:
- r:表示正在运行或者等待 CPU 调度的进程数。因为该列数据不包含 I/O 的统计信息,因此可以用来检测 CPU 是否饱和。若 r 列中的数字大于 CPU 的核数,表示 CPU 已经处于饱和状态。
- free:当前剩余的内存;
- si, so:交换分区换入和换出的个数,若换入换出个数大于 0,表示内存不足;
- us, sy, id, wa:CPU 的统计信息,分别表示 user time、system time(kernel)、idle、wait I/O。I/O 处理所用的时间包含在 system time 中,因此若 system time 超过 20%,则 I/O 可能存在瓶颈或异常;
mpstat -P ALL 1
执行这个,首先需要安装一个包,ubuntu 为例
$ apt install sysstat
$ mpstat -P ALL Linux 3.10.0-229.el7.x86_64 (localhost.localdomain) 05/30/2018 _x86_64_ (16 CPU) 04:03:55 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 04:03:55 PM all 3.67 0.00 0.61 0.71 0.00 0.00 0.00 0.00 0.00 95.02 04:03:55 PM 0 3.52 0.00 0.57 0.76 0.00 0.00 0.00 0.00 0.00 95.15 04:03:55 PM 1 3.83 0.00 0.61 0.71 0.00 0.00 0.00 0.00 0.00 94.85 04:03:55 PM 2 3.80 0.00 0.61 0.60 0.00 0.00 0.00 0.00 0.00 94.99 04:03:55 PM 3 3.68 0.00 0.58 0.60 0.00 0.00 0.00 0.00 0.00 95.13 04:03:55 PM 4 3.54 0.00 0.57 0.60 0.00 0.00 0.00 0.00 0.00 95.30 [...]
- 该命令用于每秒打印一次每个 CPU 的统计信息,可用于查看 CPU 的调度是否均匀。
pidstat 1
执行这个,首先需要安装一个包,ubuntu 为例
$ apt install sysstat
$ pidstat 1 Linux 4.4.0-53-generic (VM-173-244-ubuntu) 09/20/2018 _x86_64_ (2 CPU) 12:05:11 PM UID PID %usr %system %guest %CPU CPU Command 12:05:12 PM UID PID %usr %system %guest %CPU CPU Command 12:05:13 PM UID PID %usr %system %guest %CPU CPU Command 12:05:14 PM 0 18026 0.00 1.00 0.00 1.00 0 pidstat 12:05:14 PM UID PID %usr %system %guest %CPU CPU Command 12:05:15 PM 0 18026 0.00 1.00 0.00 1.00 0 pidstat
- 该命令用于打印各个进程对 CPU 的占用情况,类似 top 命令中显示的内容。pidstat 的优势在于,可以滚动的打印进程运行情况,而不像 top 那样会清屏。
iostat -xz 1
- 类似 vmstat,第一次输出的是从系统开机到统计这段时间的采样数据;
$ iostat -xz 1 3
Linux 4.4.0-53-generic (VM-173-244-ubuntu) 09/20/2018 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.31 0.00 0.14 0.07 0.00 99.47
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 2.80 0.21 1.82 2.83 20.98 23.54 0.03 14.02 4.23 15.13 1.11 0.22
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 1.01 0.00 98.99
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 17.00 0.00 8.00 0.00 100.00 25.00 0.11 14.00 0.00 14.00 2.00 1.60
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.50 0.00 0.00 99.50
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
检查列
- r/s, w/s, rkB/s, wkB/s,表示每秒向 I/O 设备发出的 reads、writes、read Kbytes、write Kbytes 的数量.
- await,表示应用程序排队等待和被服务的平均 I/O 时间,该值若大于预期的时间,这表示 I/O 设备处于饱和状态或者异常。
- avgqu-sz,表示请求被发送给 I/O 设备的平均时间,若该值大于 1,则表示 I/O 设备可能已经饱和;
- %util,每秒设备的利用率;若该利用率超过 60%,则表示设备出现性能异常;
free -m
$ free -m
total used free shared buff/cache available
Mem: 1872 859 205 20 807 800
Swap: 0 0 0
检查的列:
- buffers: For the buffer cache, used for block device I/O.
- cached: For the page cache, used by file systems.
若 buffers 和 cached 接近 0,说明 I/O 的使用率过高,系统存在性能问题。
Linux 中会用 free 内存作为 cache,若应用程序需要分配内存,系统能够快速的将 cache 占用的内存回收,因此 free 的内存包含 cache 占用的部分。
sar -n DEV 1
- sar 是 System Activity Reporter 的缩写,系统活动状态报告。
- -n { keyword [,…] | ALL },用于报告网络统计数据。keyword 可以是以下的一个或者多个: DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6, ICMP6, EICMP6 和 UDP6。
- -n DEV 1, 每秒统计一次网络的使用情况;
- -n EDEV 1,每秒统计一次错误的网络信息;
$ sar -n DEV 1 3 Linux 4.4.0-53-generic (VM-173-244-ubuntu) 09/20/2018 _x86_64_ (2 CPU) 12:09:54 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:09:55 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:09:55 PM eth0 11.00 8.00 0.71 0.88 0.00 0.00 0.00 0.00 12:09:55 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:09:56 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:09:56 PM eth0 12.00 12.00 0.82 1.34 0.00 0.00 0.00 0.00 12:09:56 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:09:57 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:09:57 PM eth0 18.00 18.00 1.34 3.31 0.00 0.00 0.00 0.00 Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: eth0 13.67 12.67 0.95 1.84 0.00 0.00 0.00 0.00
- IFACE ,网络接口名称;
- rxpck/s ,每秒接收到包数;
- txpck/s ,每秒传输的报数;(transmit packages)
- rxkB/s ,每秒接收的千字节数;
- txkB/s ,每秒发送的千字节数;
- rxcmp/s ,每秒接收的压缩包的数量;
- txcmp/s ,每秒发送的压缩包的数量;
- rxmcst/s,每秒接收的组数据包数量;
sar -n TCP,ETCP 1
- 该命令可以用于粗略的判断网络的吞吐量,如发起的网络连接数量和接收的网络连接数量;
- TCP, 报告关于 TCPv4 网络流量的统计信息;
- ETCP, 报告有关 TCPv4 网络错误的统计信息;
$ sar -n TCP,ETCP 1 3 Linux 4.4.0-53-generic (VM-173-244-ubuntu) 09/20/2018 _x86_64_ (2 CPU) 12:20:11 PM active/s passive/s iseg/s oseg/s 12:20:12 PM 1.00 0.00 17.00 14.00 12:20:11 PM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:20:12 PM 0.00 0.00 0.00 0.00 0.00 12:20:12 PM active/s passive/s iseg/s oseg/s 12:20:13 PM 0.00 0.00 2.00 1.00 12:20:12 PM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:20:13 PM 0.00 0.00 1.00 0.00 0.00 12:20:13 PM active/s passive/s iseg/s oseg/s 12:20:14 PM 1.00 0.00 9.00 8.00 12:20:13 PM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:20:14 PM 0.00 0.00 1.00 0.00 0.00 Average: active/s passive/s iseg/s oseg/s Average: 0.67 0.00 9.33 7.67 Average: atmptf/s estres/s retrans/s isegerr/s orsts/s Average: 0.00 0.00 0.67 0.00 0.00
检测的列:
- active/s: Number of locally-initiated TCP connections per second (e.g., via connect()),发起的网络连接数量;
- passive/s: Number of remotely-initiated TCP connections per second (e.g., via accept()),接收的网络连接数量;
- retrans/s: Number of TCP retransmits per second,重传的数量;
top
- top 命令包含更多的指标统计,相当于一个综合命令。
$ top
top - 12:21:47 up 113 days, 29 min, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 180 total, 1 running, 179 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1917264 total, 209296 free, 880528 used, 827440 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 819588 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
365 root 0 -20 0 0 0 S 0.3 0.0 0:45.27 kworker/0:1H
1688 root 20 0 1446872 9028 3416 S 0.3 0.5 104:46.91 YDService
18955 root 20 0 40816 3816 3168 R 0.3 0.2 0:00.02 top
1 root 20 0 119876 5248 3200 S 0.0 0.3 2:01.38 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 1:06.88 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root 20 0 0 0 0 S 0.0 0.0 25:42.90 rcu_sched
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root rt 0 0 0 0 S 0.0 0.0 0:13.97 migration/0
10 root rt 0 0 0 0 S 0.0 0.0 0:42.65 watchdog/0
11 root rt 0 0 0 0 S 0.0 0.0 0:34.21 watchdog/1
12 root rt 0 0 0 0 S 0.0 0.0 0:14.00 migration/1
13 root 20 0 0 0 0 S 0.0 0.0 0:58.51 ksoftirqd/1
15 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/1:0H
这个命令占全屏,可以按 q 键退出
总结
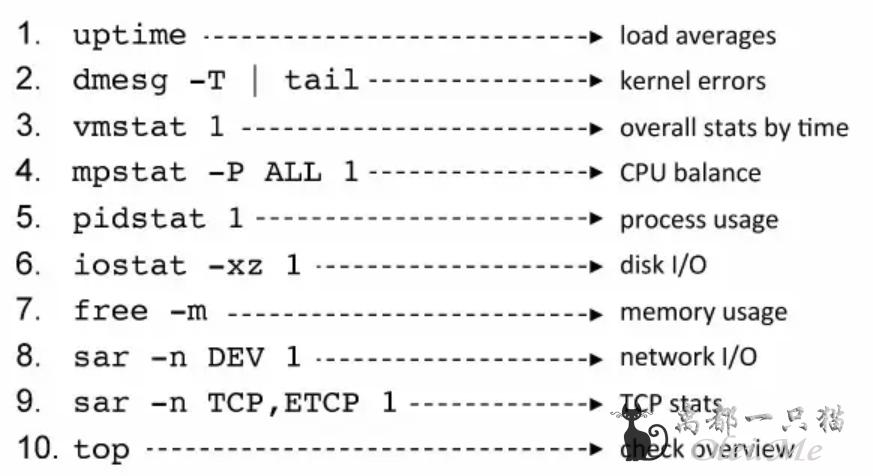
- 下面的图片很好的展示了各个命令的主要作用,如使用 vmstat 查看系统的整体性能,mpstat 用于查看 cpu 的性能,pidstat 用于查看进程的状态,iostat 用于查看 io 的状态,free 用于产看内存的状态,sar 用于产看网络的状态等。
本文作者为 olei,转载请注明。
不错,涨姿势了
杰新博客来访 [aru_11]
@杰新博客欢迎来访,友链否?~
@oleiok,老乡啊![aru_1]
@杰新博客哈哈,老乡~~已添加~
@olei 嗯 已添加!